
La creación de sistemas de predicción y recomendación están en auge, y se ha mostrado como aportan valor a las empresas que los incorporan en su día a día junto con otros sistemas de Inteligencia Artificial. Es un hecho que, en plena Revolución Digital, aplicar el Machine Learning resulta crucial para poder explotar los datos de las bases de datos de nuestra empresa. La aplicación de estrategias como los sistemas de predicción posibilitan la generación de valor de manera exponencial, o los sistemas de recomendación, que permiten maximizar ventas y facilitar la búsqueda de artículos a los usuarios. Con la aplicación de estas técnicas es posible acrecentar la productividad y obtener un mayor rendimiento.
Actualmente existe una gran cantidad de algoritmos para implementar dichas técnicas. Solicítanos presupuesto para incorporar sistemas de recomendación y predicción en tu empresa. Te asombrarán los resultados: nuestros proyectos se amortizan en menos de 2 años.
Los algoritmos utilizados en los sistemas de predicción dependerán en gran medida de las necesidades en las que se quiera dar respuesta.
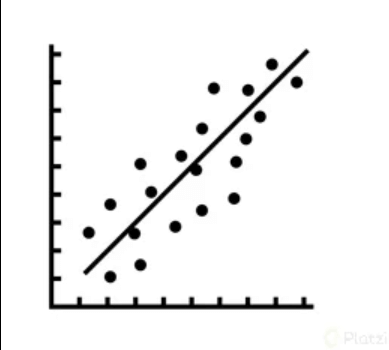
Por un lado, la regresión lineal se utiliza para generar predicciones sobre una variable que llamamos la variable dependiente, generalmente denominada con una y, dadas una o varias variables independientes, generalmente denominadas X. La variable dependiente y siempre es numérica. Una regresión lineal en su forma más simple es una línea recta en dos dimensiones que se ajusta a los valores de los datos.
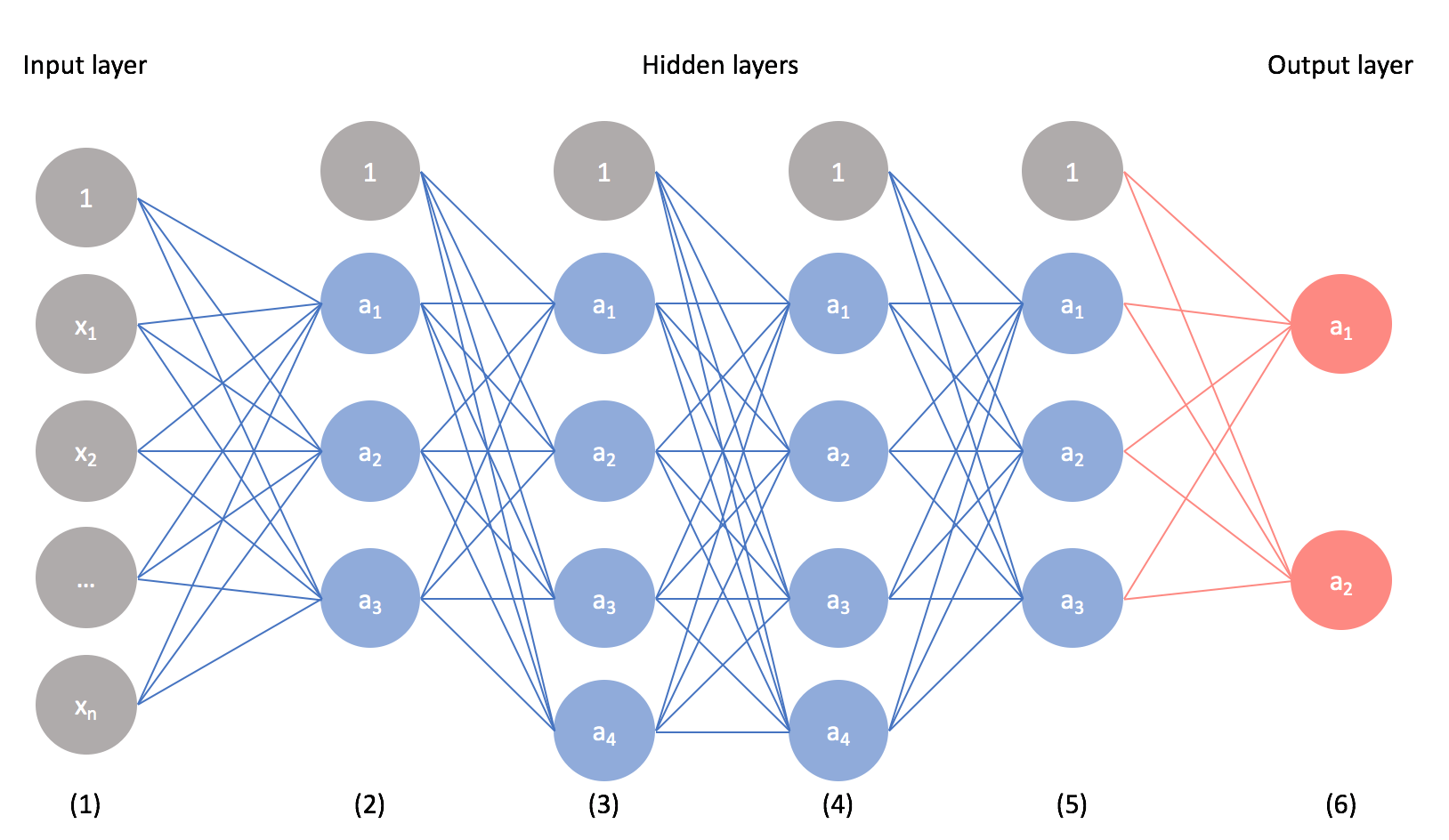
Por otro lado, una red neuronal es una red de entidades interconectadas conocidas como nodos en las que cada nodo es responsable de un cálculo simple. Por lo tanto, una red neuronal funciona de manera similar a las neuronas del cerebro humano, ya que se establecen conexiones entre nodos, se envía información, y se realizan predicciones determinadas a partir de los datos introducidos inicialmente. En las redes neuronales, la primera capa es la capa de entrada, seguida de una capa oculta y finalmente una capa de salida. Cada capa contiene una o más neuronas. Cuanto más capas y neuronas mayor efectividad en la medición de los resultados.
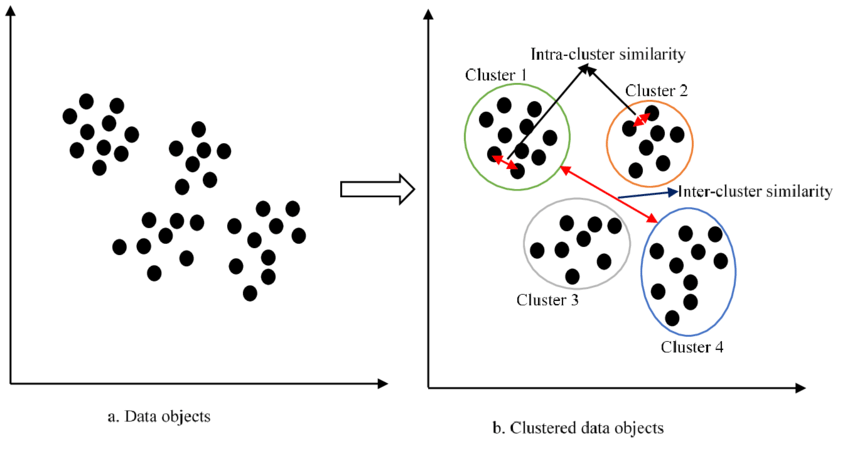
Para la técnica de Clustering solo dispondremos de un conjunto de datos de entrada, sobre los que debemos obtener información sobre la estructura del dominio de salida, que es una información de la cual no se dispone.
Otro tipo de algoritmo es el árbol de decisión, que se utiliza tanto para tareas de clasificación como de regresión. Su estructura es de árbol jerárquica y consta de un nodo raíz, ramas, nodos internos y nodos hojas.
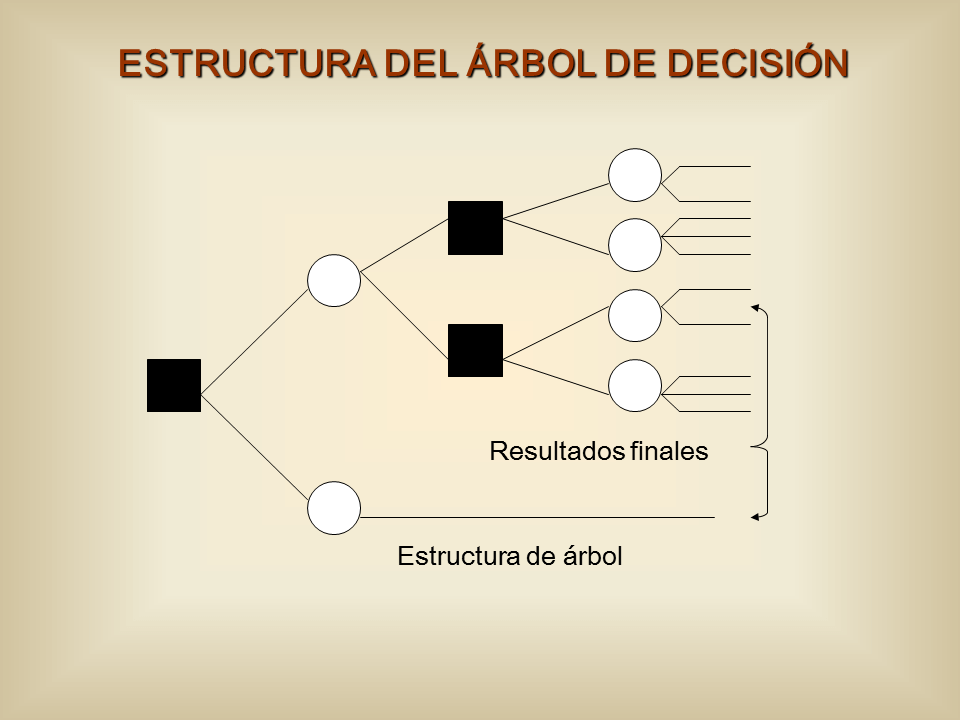
Un árbol de decisión comienza con un nodo raíz, que no tiene ramas entrantes. Las ramas salientes del nodo raíz alimentan los nodos internos. En función de las características disponibles, ambos tipos de nodos realizan evaluaciones para formar subconjuntos homogéneos, que se indican mediante nodos terminales. En función de las características, ambos nodos realizan evaluaciones para formar subconjuntos homogéneos, que se indican mediante nodos terminales. Los nodos hoja representan todos los resultados posibles del dataset.
Si bien hay varias formas de seleccionar el mejor atributo en cada nodo, dos métodos, la ganancia de información y la impureza de Gini, actúan como criterio de división popular para los modelos de árboles de decisión. Ayudan a evaluar la calidad de cada condición de prueba y qué tan bien podrá clasificar las muestras en una clase.
La entropía es un concepto que se deriva de la teoría de la información, que mide la impureza de los valores de la muestra.
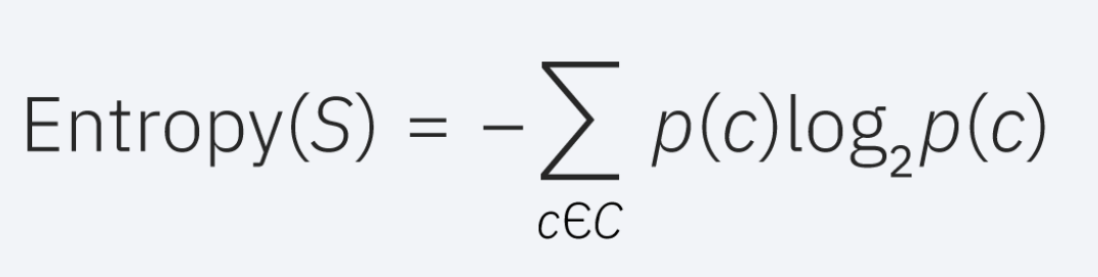
Los valores de entropía pueden estar entre 0 y 1. Si todas las muestras en el conjunto de datos, S, pertenecen a una clase, entonces la entropía será igual a cero. Si la mitad de las muestras se clasifican en una clase y la otra mitad en otra clase, la entropía estará en su punto más alto en 1. Para seleccionar la mejor característica para dividir y encontrar el árbol de decisión óptimo, se debe usar el atributo con la menor cantidad de entropía. La ganancia de información representa la diferencia de entropía antes y después de una división en un atributo determinado. El atributo con la ganancia de información más alta producirá la mejor división, ya que hace el mejor trabajo al clasificar los datos de entrenamiento de acuerdo con su clasificación de destino. La ganancia de información generalmente se representa con la siguiente fórmula:

Veamos un ejemplo implementando las fórmulas mencionadas:
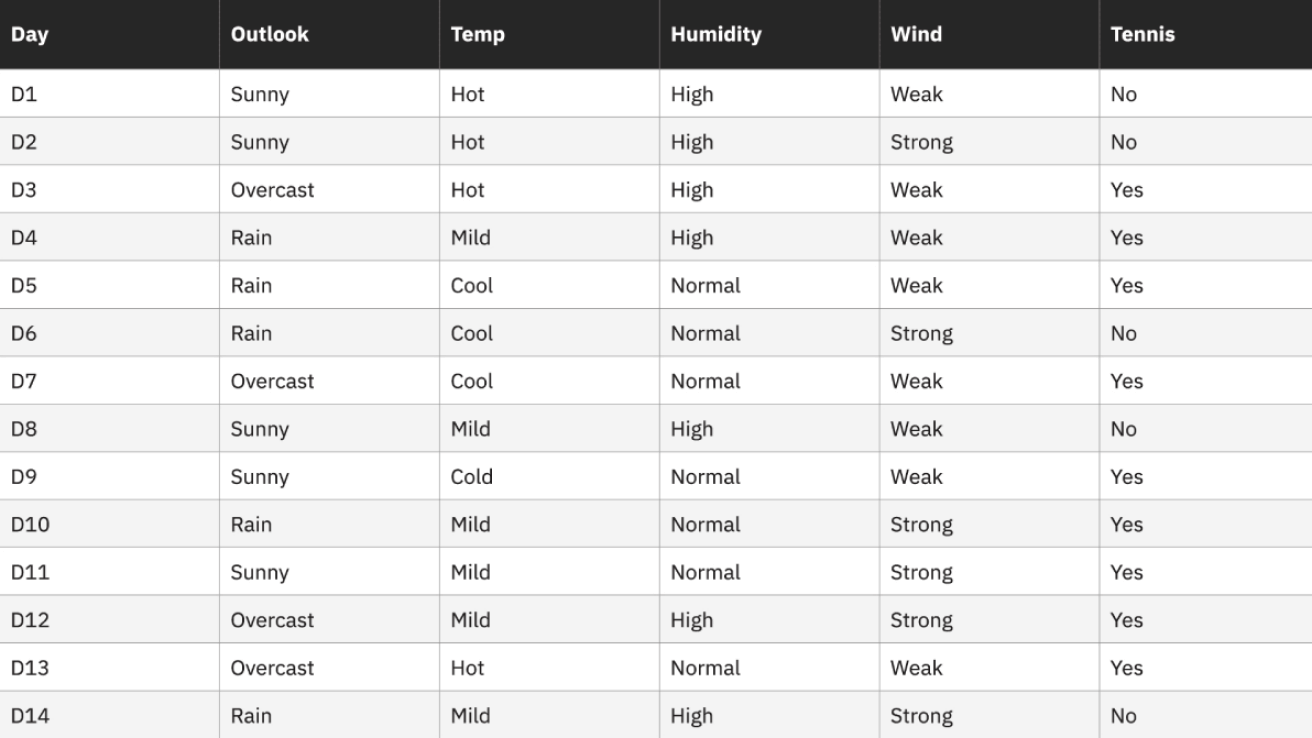
Para este conjunto de datos, la entropía es 0.94. Esto se puede calcular al encontrar la proporción de días en los que "Jugar al tenis" es "Sí", que es 9/14, y la proporción de días en los que "Jugar al tenis" es "No", que es 5/14. Luego, estos valores se pueden conectar a la fórmula de entropía anterior.
Entropía (Tenis) = -(9/14) log2(9/14) – (5/14) log2 (5/14) = 0.94
Entonces podemos calcular la ganancia de información para cada uno de los atributos individualmente. Por ejemplo, la ganancia de información para el atributo "Humedad" sería la siguiente:
Ganancia (Tenis, Humedad) = (0.94)-(7/14)*(0.985) – (7/14)*(0.592) = 0.151
En síntesis
7/14 representa la proporción de valores donde la humedad es igual a "alta" al número total de valores de humedad. En este caso, el número de valores donde la humedad es igual a "alta" es el mismo que el número de valores donde la humedad es igual a "normal".
0.985 es la entropía cuando Humedad es = a "alta"
0.59 es la entropía cuando Humedad es = a "normal"
La impureza de Gini es la probabilidad de clasificar incorrectamente un punto de datos aleatorio en el conjunto de datos si se etiquetara en función de la distribución de clases del conjunto de datos. Similar a la entropía, si el conjunto S es puro (es decir, pertenece a una clase), entonces su impureza es cero. Esto se denota mediante la siguiente fórmula:

Los árboles de decisión poseen varias ventajas como por ejemplo su fácil interpretación, la poca preparación necesaria para los datos y su flexibilidad al poder aprovecharse en tareas de regresión y clasificación por el contrario son propensos al sobreajuste, son estimadores de alta varianza y pueden ser más costoso a la hora de entrenar que otros algoritmos. Además, no son totalmente compatibles con scikit-learn, ya que no admiten variables categóricas.
En cuanto a los sistemas de recomendación podremos diferenciarlos en base los contenidos, las valoraciones (de recomendación colaborativa), la información demográfica o una combinación de ambas (de recomendación híbridos).
Para implementar un algoritmo de filtrado colaborativo el primer paso es construir una matriz usuario-elemento. Una matriz usuario-elemento comprende usuarios individuales en las filas y elementos individuales en las columnas.
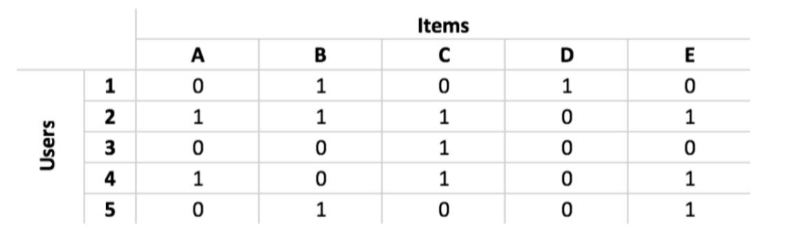
Las filas de esta matriz representan a cada usuario y las columnas a cada elemento. Los valores de cada celda representan si el usuario en cuestión ha recomendado un determinado artículo. Por ejemplo, el usuario 1 ha recomendado los artículos B y D y el usuario 2 ha recomendado los artículos A, B, C y E. Necesitamos construir primero la matriz usuario-elemento. El siguiente paso es calcular las similitudes entre los usuarios. Para medir las similitudes, se suele utilizar la similitud de los cosenos. La ecuación para calcular la similitud del coseno entre dos usuarios es la siguiente:
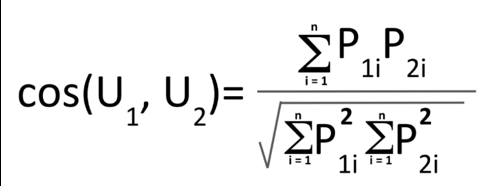
En esta ecuación, U1 y U2 representan al usuario 1 y al usuario 2. P1i y P2i representan cada producto, i, lo que el usuario 1 y el usuario 2 han recomendado. Si se utiliza esta ecuación, se obtendrá 0,353553 como la similitud del coseno entre los usuarios 1 y 2 en el ejemplo anterior y 0,866025 como la similitud del coseno entre los usuarios 2 y 4. Cuanto mayor sea la similitud del coseno, más parecidos serán los dos usuarios. Así en nuestro ejemplo, los usuarios 2 y 4 son más similares entre sí que los usuarios 1 y 2. El enfoque de filtrado colaborativo basado en el usuario utiliza las similitudes entre los usuarios. Por otro lado, el enfoque de filtrado colaborativo basado en el elemento utiliza las similitudes entre los elementos. Esto significa que cuando calculamos las similitudes entre los dos usuarios en el filtrado colaborativo del enfoque basado en el usuario, tenemos que construir y utilizar una matriz usuario-elemento como hemos comentado anteriormente. Sin embargo, para el enfoque basado en elementos, necesitamos calcular las similitudes entre los dos elementos, y esto significa que necesitamos construir y utilizar una matriz de elemento a usuario, que podemos obtener simplemente transponiendo la matriz de usuario a elemento.
Conclusiones
Actualmente adquirimos de manera online, una gran parte del entretenimiento, conocimiento, bienes y artículos que son necesarios en nuestra vida cotidiana. Podemos observar cómo progresivamente, los portales donde compramos, las redes sociales en las que interactuamos y las plataformas multimedia, han ido evolucionando de tal manera que poseen la capacidad de realizar sugerencias personalizadas y adaptadas a los intereses de los internautas, todo ello gracias a la implementación de sistemas de recomendación. A su vez los sistemas de predicción son útiles en áreas como por ejemplo las finanzas al estimar el riesgo de activos financieros, en la medicina, para el diagnóstico de enfermedades o en el desarrollo de automóviles autónomos. A modo de reflexión, Amazon consigue el 35% de su facturación, lo que equivale a casi 400.000M $ (cifra de facturación de 2020), por el uso de estos tipos de sistemas. Por ello estas técnicas son claves para el futuro y desarrollo de la sociedad y para la optimización del rendimiento en el sector tecnológico, y empresarial.
Desde Overstand Intelligence, te animamos a lanzarte a la piscina y emprender tu proyecto basado en inteligencia arficicial. Contáctanos para pedir presupuesto de tu proyecto de IA ahora, totalmente sin compromiso. Mientras lees esto, tu competencia avanza.
